
How we Rebuilt the AngelList Platform for India

In September 2024, we launched AngelList India’s newly developed platform, a complete rewrite tailored to the Indian investing ecosystem. It introduced unique investor and product flows, adapted seamlessly to Indian regulations, and ran on a technology stack built from scratch.
Why build our own platform for India?
Because the Indian startup and investment ecosystem is unique. For over six years, we shared the AngelList US platform, but a few key reasons motivated us to build our own:
- Data residency and regulatory compliance: Indian regulations mandate that investor data remain within the country. Strict data separation became impractical on a shared platform.
- Tailored for India: Investors, fund managers, and founders here work with different fund structures, deal flows, and compliance processes than in the US.
- Technical debt: Country-specific logic was scattered throughout the codebase. Supporting two divergent product flows slowed development and increased the risk of bugs, frustrating engineering teams in both regions.
Clone vs Rewrite: Our decision process
When we set out to build our own platform, we faced a fundamental choice: clone the existing platform as-is or rewrite from scratch.
Cloning would have given us a running start:
Rewrite would give us more control:
This was not a decision we wanted to make on a whim. We broke down product flows, the database schema, and the complexity of migration to understand exactly what it would take. In the end, the analysis made the choice clear: we would rewrite from scratch. It was the harder path, but also the only one that gave us control, eliminated technical debt, and ensured full compliance with India’s data residency requirements.
Scoping the rewrite: What were we actually using?
Our first step was to map exactly what Indian users and the operations team relied on in the old platform.
We created a FigJam board and manually collected screenshots of every page, action, and workflow. This gave us a complete visual map of the product surface area in use.
At the same time, we ran user and team interviews to dig deeper into:
- Which actions they performed, and how frequently
- Which features they liked or disliked
- Which parts of the product were confusing, especially for Indian investors
- Which terminologies felt intuitive (so we could preserve them)
- What improvements they wanted on each screen or workflow
Here is a sample from our study:
This exercise became the starting point of our rebuild. From here, we could work backwards to:
- Identify the code paths and product flows actually in use
- Decide which data models to retain, redesign, or retire
- Design better UI/UX for Indian investors and fund managers
- Clearly separate essentials from nice-to-haves
- Lay out a complete roadmap (with a task board) from MVP to production launch
Data Modelling: Simplify or Remove
The original schema had evolved over years. The database was split across three different microservices with complex schemas and overlapping data points. We didn’t need that level of complexity for an India-specific application.
We made a deliberate choice to consolidate everything into a single, unified data model designed specifically around our product needs. This meant carefully reviewing every service and data point, and then:
- Removing tables and columns that didn’t apply to Indian workflows
- Merging data models from different microservices and resolving overlaps
- Simplifying relationships between tables
- Pruning redundant or legacy fields
This was a high-risk process, and we handled it with extreme caution. Everything was manual, deliberate, and verified.
We verified column by column before deleting anything. For table relationships, we mapped the sprawl, traced active linkages, and eliminated broken or unnecessary joins.
Example: Thecommitmentstable
Before: two versions (42 and 29 columns) across different services, with US-only fields and multiple currency support.
After: one 13-column table, INR-only, tailored to Indian flows.
This exercise gave us a clearer understanding of the platform, challenged our assumptions, and exposed hidden data dependencies. It also sharpened our data modelling practices and revealed the reasoning behind past design choices. It became a technical rediscovery of the product we had inherited.
Technology Stack: Easy to Operate
Admittedly, this was the easiest part of the rewrite. We optimised for simplicity, ease of hiring, and performance - in that order.
Principles
- No big frameworks: We had in-house expertise to build only what we needed, avoiding the complexity and overhead of large frameworks.
- JavaScript end-to-end: The US platform used Ruby on Rails, which is great but harder to hire for in India. We chose JavaScript so every engineer could work full-stack without context switching.
- GraphQL (a controversial choice): Our team knows it inside out. A single typed schema allowed engineers to ship features front to back effortlessly.
- Simple, pragmatic hosting: Docker Swarm fit our traffic profile, letting us keep ops lean. The frontend was hosted on Vercel for speed and simplicity.
High-level Architecture
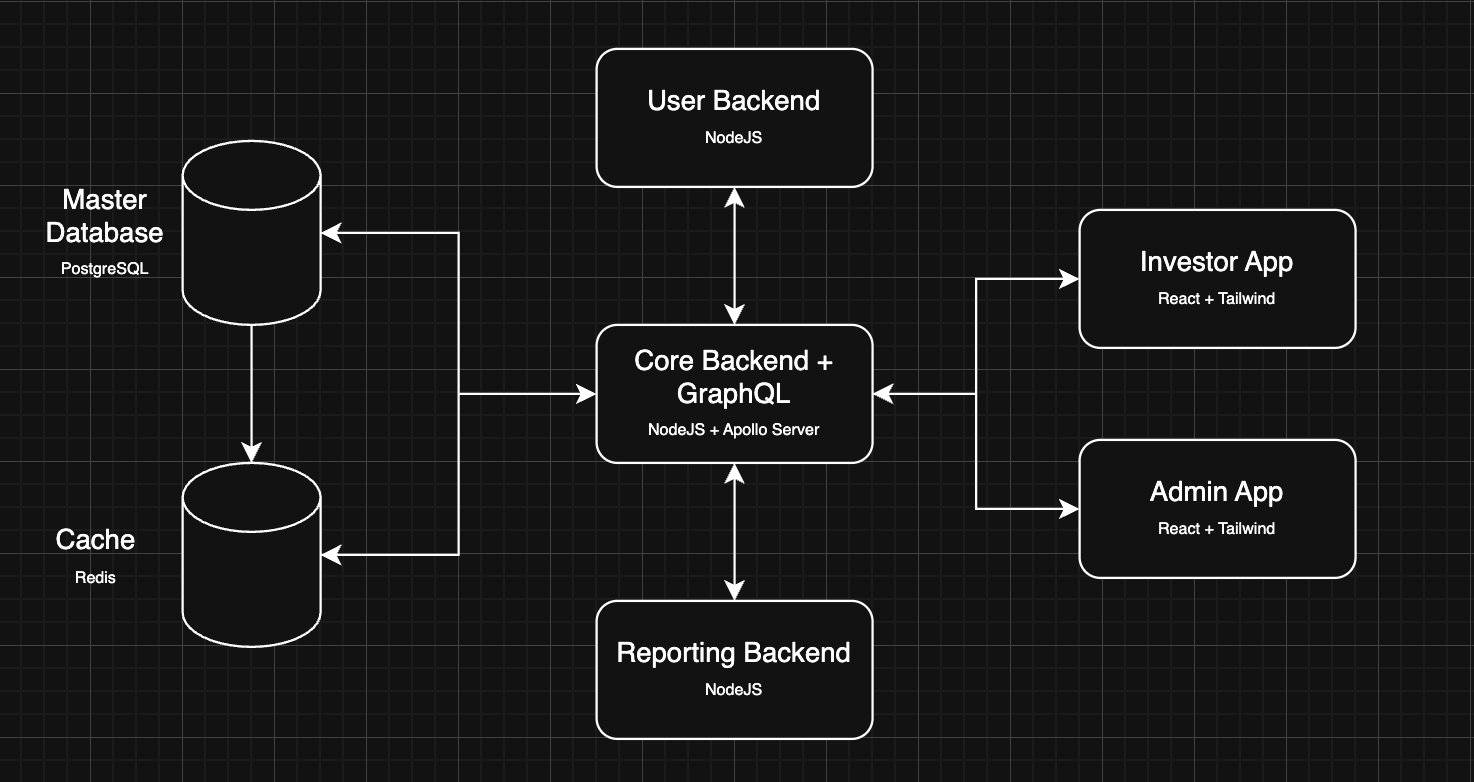
Functional Overview
- Investor App: The main application used by investors; built with react, Tailwind, and GraphQL
- Admin Dashboard: Internal ops console, same stack, same GraphQL schema
- Core Backend: Business logic + GraphQL Relay; routes to User Management and Reporting
- User Management Backend: Handles authentication and authorisation
- Reporting Backend: Generates investor statements, regulatory reports, and analytics
- Postgres DB: Secure transactional store, backed up regularly
- Redis Cache: Speeds up queries with frequently accessed data
Key Highlights
- GraphQL Object Notation: Instead of SDL, schemas were defined in JavaScript object notation, for example:
const UserType = new GraphQLObjectType({
name: 'User',
fields: {
id: { type: GraphQLID }
}
});
- Scalable by Service Isolation: Core, User Management, and Reporting ran as independent Node.js services with strict bounded contexts. This prevented resource contention (for example, memory spikes in the report generator wouldn’t affect transactions) and enabled targeted horizontal scaling of heavy services without over-provisioning others.
- Reusable Frontend Components: Core UI elements such as forms, tables, and error messages were built as reusable React components. All styling lived in a shared top-level design system—no route had its own CSS. This kept the UI consistent, made it easy for any developer to add features, and avoided technical debt.
<DataTable
data={investments}
onClick={}
columns={[
{ label: 'Startup', fieldName: 'startup.name' },
{ label: 'Amount Invested', fieldName: 'amount' },
{ label: 'Date', fieldName: 'createdAt' },
]}
/>
- Self-Contained Page Design: Every page followed a strict, top-to-bottom pattern so all logic, data, and UI composition lived in one file. Developers didn’t need to chase dependencies to make a change—lowering cognitive load, speeding delivery, and reducing side effects.
Standard layout (contracted):
// 1) Imports — components, hooks, types
// 2) Query definition — gql`...`
const Page = () => {
// 3) useQuery — variables, fetchPolicy
// 4) Loading — <LoadingIndicator />
// 5) Error — <ErrorMessage ... />
// 6) Render — dialogs + reusable components (e.g., <DataTable ... />)
};
Why it worked: Predictable structure, co-located queries/types/handlers, easy diffing and reviews, and safer edits (no deep chain spelunking).
- No Speculative Development: Every feature was carefully planned and tied to a validated need. We planned ahead where it mattered—security, compliance, and architecture—but avoided adding “maybe useful” features. This kept the codebase lean, free of dead paths, and ensured every part was actively used and maintained.
- Strict Code Discipline: Every PR made exactly one focused change. Code had to be self-explanatory through clear naming, with no unnecessary comments, and complex logic was broken into simple, composable functions. Commit messages were precise and described exactly what changed and why, ensuring a clean, maintainable history.
These practices ensured that our rewrite had a deliberate, maintainable foundation. By keeping the stack lean, the architecture modular, and the codebase disciplined, we shipped confidently without accruing technical debt. This discipline became the backbone for rapidly achieving full feature parity with the US platform.
Achieving Feature Parity:
On that foundation, we set out to replicate every feature Indian investors relied on so the new platform felt complete and seamless from day one:
- Building it out: We analysed every flow, mapped every data model, and built on a strong technical foundation. The first 80% of the platform came together relatively smoothly. The final 20% was a grind, requiring us to decode past decisions, align with team needs, and refine the end-user experience.
- Keeping it similar in UI/UX: While we could have radically changed the design, we prioritised familiarity. Core flows and terminology stayed consistent so users didn’t have to relearn the product, even as we introduced a cleaner, more distinct design.
- Prioritising critical investor flows first: We focused on onboarding, deal creation, and reporting before tackling lower-impact features. This ensured the platform could be production-ready as early as possible.
- Continuous feedback from ops and investors: We worked closely with our operations team and a group of power users to test parity milestones, catching mismatches in behaviour or language before they became entrenched.
- Sprint-based, module-by-module delivery: We divided the platform into modules (investor flows, admin tools, reporting, compliance) and delivered them in focused sprints, fully completing and validating each before moving on.
Achieving parity was only half the battle. The other half was ensuring that every investor record, deal, and compliance detail from the past decade carried over intact.
Data Migration Strategy
Migrating that much data was as critical as it was risky. We brought production data in early so we could be sure of our interfaces, logic, and workflows. We deliberately avoided designing fallback logic. If something broke or was missing, we wanted to know immediately. Our approach had three parts:
- Sourcing: We first tried cloning the old database with SQL/Python scripts, but quickly ran into fields that needed business context. For example, calculating historical valuations required applying our internal USD-to-INR rates based on transaction dates. To handle cases like this reliably, we wrote Ruby scripts to export the necessary data from the legacy system into our new database.
- Adapting: We started with our idealised data model, created the necessary tables, and ran the import scripts. Any failing constraints (for example, nullability or data type mismatches) were addressed by either fixing the script or adjusting the database schema. This process was iterative. We constantly moved data, tested business logic and UI, and rolled back or partially re-migrated data depending on the issue. For instance, we might fix an incorrect currency conversion in a single table or re-import an investor’s entire investment record.
- Validating: We ran evaluation queries against trusted figures from the old platform, such as total investors, total investments, valuations, and syndicate amounts. These checks surfaced both migration gaps and issues in the legacy data itself, from misconfigured entities to broken relationships, giving us confidence in accuracy before launch.
After sourcing, adapting, and validating the data, we were confident it was complete but not yet production-ready. Every migrated record still needed to pass the same rigorous checks as the features built around it, which is where our testing process began.
Testing, Testing, Testing
From the very first feature, we tested with unit, integration, and end-to-end checks. But the bigger challenge was proving the accuracy of migrated data, where even a single missing investment, miscalculated valuation, or incomplete KYC record could undermine trust.
Automated evaluations against old platform metrics helped, but they were not enough. To close the gap, we added an exhaustive manual verification process to catch issues that software alone could not.
Our team split into three groups:
- Legal: Collected and reviewed the legal documents for each deal, investment, and fund
- Operations: Gathered historical valuation data and verified calculations
- Engineering: Compared data from the old platform, the new platform, and the source of truth in company documents
We manually reviewed every deal, investment, fund, and syndicate from the past six years. Each discrepancy was documented, triaged, and sent to the right team: engineering fixed database or migration script issues, and operations reached out to investors or companies to correct underlying records.
It was a rigorous, all-hands effort, checking everything, everywhere, until every number and record was perfect.
After months of building, migrating, and verifying, we were confident the platform was feature complete and the data flawless. The final challenge was executing the cutover from the old system to the new without disrupting investors or deals in progress. That is where our hot-swap plan came into play.
The Hot-Swap
A hot-swap means switching every user to the new platform at once, shutting off the old system the moment the new one goes live.
When we began the AngelList India project, our plan was to run a parallel platform alongside the old one, giving investors time to adapt and sunsetting it gradually, as most companies do. But constraints around data residency, a lean team, and the inability to add more technical debt to the old platform, combined with the fact that such a project would take years, meant we had to commit to a direct cutover. It was like changing the wheels on a moving bus.
We could not afford for it to fail, so we spent months simulating the switchover and planning for every possible failure scenario. The final plan looked like this:
- Select a cutover window: 4 hours, between 12 a.m. and 4 a.m., when traffic was lowest
- Lock the old platform: Convert it to read-only and display prominent banners informing users about the upcoming switch and the new platform link
- Proactive communication: Notify users via email and in-platform messages, assuring them their data was safe
- Final migration: At the start of the window, migrate all remaining changes from the old system to the new
- Maintenance mode: Keep the new platform offline to users while migration ran
- Post-migration testing: Select a group of users to verify data and functionality end to end before going live
- User onboarding: Invite all users to the new platform via email
- Simplified login: Switch from password-based login to OTP-based email login, avoiding password migration (which could compromise the US platform’s security)
- Monitor adoption: Track logins on the new platform and only remove read access and banners from the old one once adoption reached a safe threshold
- Full team on comms: Every member of the team was on standby during the window, monitoring channels for any user-reported issues and ready to respond immediately
- Rollback contingency: If anything went seriously wrong, we had a full rollback plan to revert changes and retry the migration at another time
By the time we executed the hot-swap, we had rehearsed it more than ten times. On the night itself, it went exactly to plan.
Life after Launch
We launched on September 5, 2024. The overall feedback on the improved flows and cleaner design was overwhelmingly positive.
The first month was spent stabilising the platform: testing continuously, migrating any missed data, and fixing bugs or issues reported by users. Once things settled, the pace accelerated dramatically:
- Automated exit and unit statements: A process that previously took weeks and required legal, operations, and engineering teams now ran in a few clicks
- Weekly feature releases: We shipped new functionality every single week
- Frictionless onboarding: Built seamless sign-up flows for both investors and founders
- India-first experience: Converted all terminology and workflows to be fully India specific
- Faster operations: A single source of truth and customised dashboards for each team member improved decision making and reduced turnaround time
- Mobile app in progress: We are now well on our way to launching our mobile experience
Reflections
- Rewriting was the hardest path: The months leading up to launch were filled with sleepless nights and constant problem solving. We knew the risks (see Joel Spolsky’s Things You Should Never Do), but once we launched, it was clear we had made the right choice.
- Discipline compounds: We were unwavering in what we built and how we built it, never compromising on code quality or data integrity. Today, we can ship features faster, with confidence in both the system and the data it runs on.
- A foundation for the future: The rewrite gave us complete control over our stack, data model, and architecture. We can now adapt the platform to new regulations, scale to support more investors and deals, and launch entirely new products such as our upcoming mobile app, without the baggage of legacy constraints.
In the end, this rewrite was not just about technology. It was about independence, control, and the ability to shape AngelList India for the market we serve. We now have a platform that reflects the realities of Indian investing, is resilient enough to scale with the ecosystem, and gives our team the confidence to innovate at speed. The hard path became our biggest advantage.